Google releases massive visual databases for machine learning
Millions of images and YouTube videos, linked and tagged to teach computers what a spoon is.

It seems like we hear about a new breakthrough using machine learning nearly every day, but it's not easy. In order to fine-tune algorithms that recognize and predict patterns in data, you need to feed them massive amounts of already-tagged information to test and learn from. For researchers, that's where two recently-released archives from Google will come in. Joining other high-quality datasets, Open Images and YouTube8-M provide millions of annotated links for researchers to train their processes on.
The Open Images set comes from a collaboration between Google, Carnegie Mellon and Cornell, with 9 million entries that were tagged by computers first before having those notes verified and corrected by humans. The Google Research team says it has enough images to train a neural network "from scratch," so if you'd like to try your hand at a DeepDream-style project, better version of Google Photos or the next Prisma then it's ready to go.
Announcing YouTube-8M: A Large and Diverse Labeled Video Dataset for Video Understanding Research – https://t.co/kxLUxGpLxU pic.twitter.com/J6n6TyIwLb
— Google Research (@googleresearch) September 28, 2016
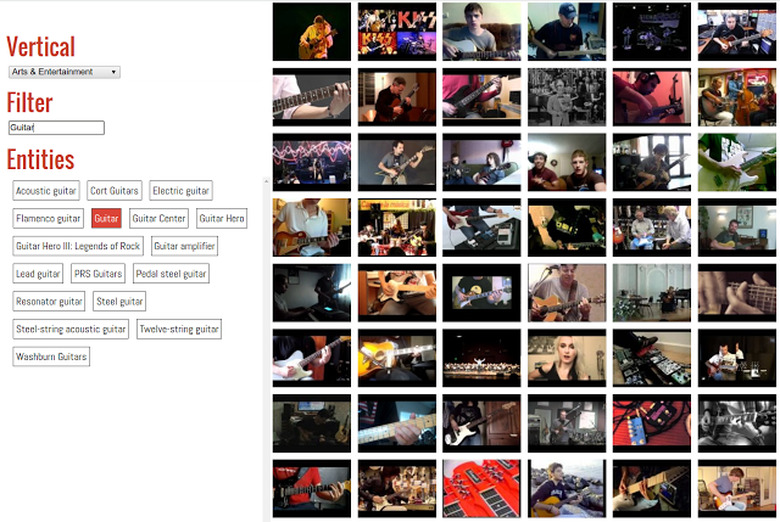
On the other hand, the YouTube8-M file points to 8 million videos (adding up to more than 500,000 hours of footage) that the group says "represents a significant increase in scale and diversity compared to existing video datasets." The idea here is to create a library for video analysis that rivals those already in existence for still images, that's also accessible for people without big data. Part of that is because Google has also extracted and tagged still images from the videos for researchers to download. Whether you're working on the next self-driving car AI or something simpler, you can browse or download the database right here.