This election proved you're only as good as your data
Trump's win shows our polling industry needs a lot of work.

As you've probably heard, while Hillary Clinton won the majority of the popular vote, Donald Trump was awarded more than 270 votes in the Electoral College. Many, particularly on social media, were incredulous, partly at the candidates but also at the pollsters — in particular, famous polling analysts like Nate Silver from Disney's FiveThirtyEight blog. Silver rose to fame as the guy who successfully predicted the past few presidential elections. In 2008, he correctly predicted 49 of 50 states, and in 2012 he nailed all 50. With that, plus an impressive showing in the midterms, a legend was born. The 2016 presidential election was not so kind to FiveThirtyEight, with misses in the battlegrounds of Florida, North Carolina, Pennsylvania, Michigan and Wisconsin turning the odds quickly in favor of Trump. But throughout nearly the entire general election campaign, Mrs. Clinton was an overwhelming favorite.
So the question is: What went wrong? There are explanations all over the internet this week, but there's one that should not be overlooked: Polling ...
FiveThirtyEight is one polling aggregator, but the Princeton Election Consortium, the Huffington Post, Daily Kos, RealClearPolitics and the New York Times' Upshot all do some form of polling aggregation. The premise behind a polling aggregator is simple elementary statistics. Each poll is a sample with a certain sample size, but if you aggregate the polls, you can increase the sample size, decrease the variance and make a better estimate of the true values.
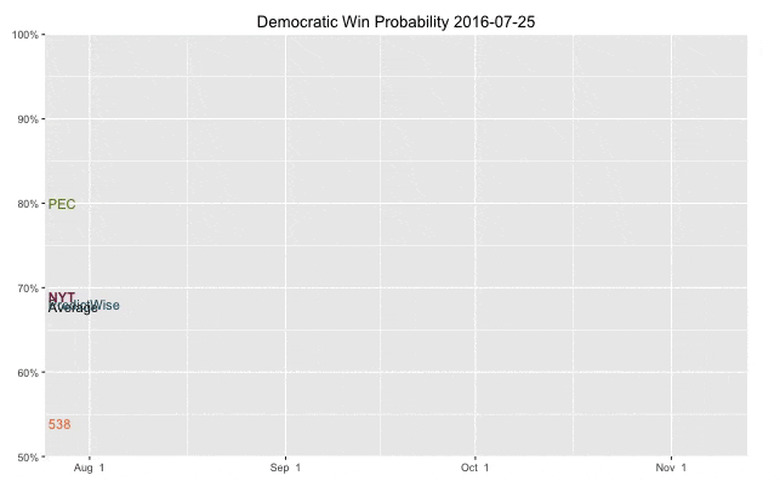
Everyone has a slightly different way of doing this to draw their conclusions. Princeton Election Consortium treats each state as an individual probability and then calculates an overall probability. FiveThirtyEight runs a series of corrections, then simulates what the results might be given the data numbers they're left with and a series of assumptions (like states flock together). RealClearPolitics just runs a raw average. You can quibble with some of the assumptions and operations of the models, and a few do, but there is a diversity of approaches that should, given good polling, reflect the true state of the race. FiveThirtyEight, in particular, was criticized quite a bit during the election season for wild swings in the model — most notably by Chris Arnade and Nassim Taleb. (The criticism goes that wild swings in the model increase uncertainty, which means the odds should be 50/50.) That being said, FiveThirtyEight's model was consistently one of the most conservative, yet it still went into Election Night with Hillary Clinton favored by a 2:1 margin. Many were shocked, understandably, to see things change so quickly.
From month before election to 9 days before it, we had 80 live interview polls in 2012 in 10 states closest to national vote. In 2016? 36.
— (((Harry Enten))) (@ForecasterEnten) November 1, 2016
Possible explanation 1: Quantity of the data
Let's look at the polls from three Upper Midwest states that had large polling errors in 2016 and compare them to polls from the previous two presidential elections.
| NUMBER OF POLLS CONDUCTED | ||||
| Michigan | Ohio | Wisconsin | Total | |
|---|---|---|---|---|
| 2008 | 11 | 25 | 16 | 52 |
| 2012 | 10 | 13 | 12 | 35 |
| 2016 | 9 | 18 | 10 | 37 |
| Percent decrease 2008-2016 | 18% | 28% | 37.5% | 28.8% |
There were significant decreases from 2008 to 2012 and 2016. Polls were still happening in these states, so you could still make an assessment of the race, but every decrease in the number of polls causes an increase in the likelihood of a polling error.
Let's consider how much the RealClearPolitics polling average differed from the final results in these same three Rust Belt states.
| POINT DIFFERENCE BETWEEN ACTUAL RESULT AND ESTIMATE | ||||
| Michigan | Ohio | Wisconsin | Total | |
|---|---|---|---|---|
| 2008 | 2.9 | 2.1 | 2.9 | 2.63 |
| 2012 | 5.5 | 0.1 | 2.7 | 2.76 |
| 2016 | 3.7 | 5.1 | 7.5 | 5.43 |
Considered in aggregate, it does appear that the polling misses have increased in these Rust Belt states as poll volume has decreased.
The decrease could be the result of budget cuts across the newspaper industry. If newspapers and journalism have less funding, polling could be one of the first things to go. Live interview polls, which are regarded to be the most accurate, require paying someone to call participants, likely a third-party company, and can become quite expensive. If places like FiveThirtyEight are simply using these polls to aggregate results, and polls are driving clicks to FiveThirtyEight and not the newspaper, it's hard to justify this use of time and money.
Possible explanation 2: Data quality
A poll requires a simple random sample to be able to make inference about the true mean of the population. If everyone in the population is not equally likely to get selected, it's not a random sample of the whole population, and if you can't acquire a random sample, then any conclusions you make about the state of the race are flawed.
The 1991 Telephone Consumer Protection Act banned the use of random dialers on cell phones, so pollsters have had to rely on people calling individuals on cell phones. Many of us don't pick up calls from unknown numbers. Surveyors are spending more time and money calling more people and having a harder time getting responses, and thus getting appropriate samples.
We could certainly look into online polling instead, but random sampling there is not foolproof either. Not everyone is online, and people are reluctant to respond to internet surveys.
Pollsters have an ideal representative sample, based on the electorate they're trying to poll. If they aren't able to get a representative random sample, they will count the responses of the individuals they do get more times (called weighting) to reach their desired sample. If a demographic that is harder to reach via cell phone or internet goes heavily towards one candidate, the chances of a polling error increase.
These are methodologically sound ways of dealing with response bias, but they are not preferred to actual simple random samples. The much-maligned LA Times poll was weighing one black Trump supporter 30 times more than the average participant in the poll, and 300 times more than the least weighted.
Possible explanation 3: Misleading data
Trump surrogates had been claiming for months that there was a "hidden" Trump vote. Social desirability bias, a term coined by social scientists, is a type of polling-response bias where individuals don't share their true preferences in a poll because they desire to be viewed favorably by the person polling them. This type of bias is more common in live interview polls than in online polls. If Trump supporters were misrepresenting their preferences, it would have skewed the polls toward Clinton and resulted in a polling miss.
Possible explanation 4: Uncertainty
Nate Silver had been arguing for weeks that while it looked like Clinton would win, this was far from certain, mostly due to a high number of undecided and third-party voters. The results showed that a huge number of late-breaking voters in the deciding states went for Trump. If uncertainty was present all along, it's entirely possible that the polls were right, but people weren't accounting enough for the uncertainty.
Polling has become both easier than ever because of our increased ability to process large amounts of data quickly and harder than ever because of our increased reliance on our phones, among other things. The polling industry has not caught up with these changes. We simultaneously know more than ever and less than ever. As we look toward the 2018 midterms and the 2020 general election, expect a lot of discussion about how to make online polls more accurate to decrease the uncertainty and reduce our reliance on live interview polls for accurate results.