Meta's latest AI suite makes speech translation more seamless and expressive
If you're whispering, so should your translated speech, right?
Back in August, Meta unveiled its multimodal AI translation model, SeamlessM4T, which supports nearly 100 languages for text and 36 for speech. With an updated "v2" architecture, the tech giant is now expanding on this tool to make conversational translations more spontaneous and expressive — the latter a missing key to an authentic conversation across languages.
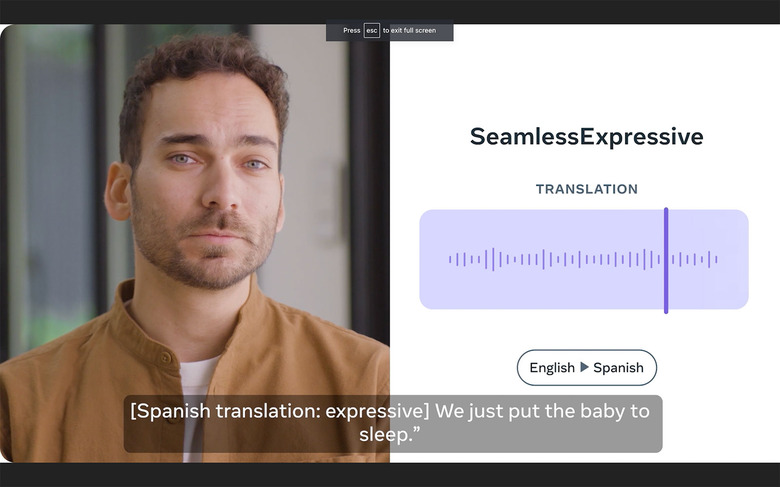
The first of the two new features is "SeamlessExpressive" which, as you can tell by the name, ports your expressions over to your translated speech. These include your pitch, volume, emotional tone (excitement, sadness or whispers), speech rate and pauses. Considering how translated speeches had always sounded robotic until now, this breakthrough is potentially a game-changer — both in our daily lives and also in content production. Supported languages include English, Spanish, German, French, Italian and Chinese, though the demo page is missing Italian and Chinese at the time of writing this article.
The second feature is "SeamlessStreaming," which starts translating a speech while the speaker is still talking, thus allowing others to hear a translation faster. There's still a short latency of just under two seconds, but at least you won't have to wait until someone finishes a sentence. According to Meta, the challenge here is that different languages have different sentence structures, so it had to develop an algorithm dedicated to studying partial audio input, in order to decide whether there's enough context to start generating a translated output, or whether to keep listening.
Meta's latest development on this "Seamless Communication" suite seems to be an impressive one — more so than the mobile interpreter tools offered by the likes of Google and Samsung. There's no word on when the public will be able to utilize these new features, but I can already imagine Meta baking them into its smart glasses some day, making them even more practical than ever.