AI is coming for big pharma
And it might wind up designing the next wonder cure.

If there's one thing we can all agree upon, it's that the 21st century's captains of industry are trying to shoehorn AI into every corner of our world. But for all of the ways in which AI will be shoved into our faces and not prove very successful, it might actually have at least one useful purpose. For instance, by dramatically speeding up the often decades-long process of designing, finding and testing new drugs.
Risk mitigation isn't a sexy notion but it's worth understanding how common it is for a new drug project to fail. To set the scene, consider that each drug project takes between three and five years to form a hypothesis strong enough to start tests in a laboratory. A 2022 study from Professor Duxin Sun found that 90 percent of clinical drug development fails, with each project costing more than $2 billion. And that number doesn't even include compounds found to be unworkable at the preclinical stage. Put simply, every successful drug has to prop up at least $18 billion waste generated by its unsuccessful siblings, which all but guarantees that less lucrative cures for rarer conditions aren't given as much focus as they may need.
Dr. Nicola Richmond is VP of AI at Benevolent, a biotech company using AI in its drug discovery process. She explained the classical system tasks researchers to find, for example, a misbehaving protein – the cause of disease – and then find a molecule that could make it behave. Once they've found one, they need to get that molecule into a form a patient can take, and then test if it's both safe and effective. The journey to clinical trials on a living human patient takes years, and it's often only then researchers find out that what worked in theory does not work in practice.
The current process takes "more than a decade and multiple billions of dollars of research investment for every drug approved," said Dr. Chris Gibson, co-founder of Recursion, another company in the AI drug discovery space. He says AI's great skill may be to dodge the misses and help avoid researchers spending too long running down blind alleys. A software platform that can churn through hundreds of options at a time can, in Gibson's words, "fail faster and earlier so you can move on to other targets."
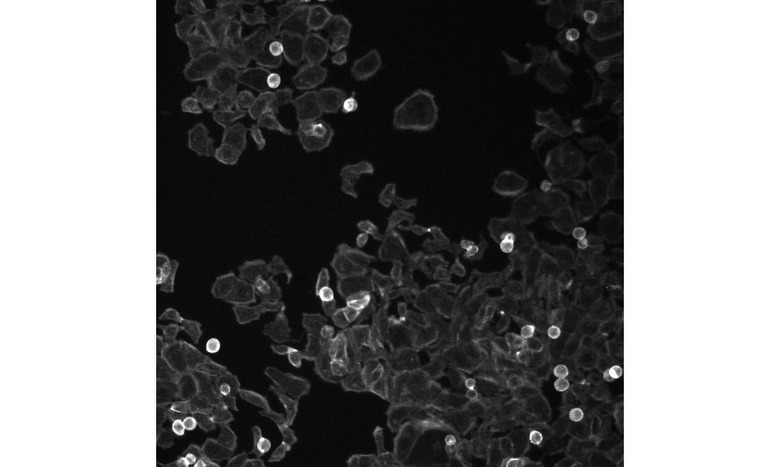
Dr. Anne E. Carpenter is the founder of the Carpenter-Singh laboratory at the Broad Institute of MIT and Harvard. She has spent more than a decade developing techniques in Cell Painting, a way to highlight elements in cells, with dyes, to make them readable by a computer. She is also the co-developer of Cell Profiler, a platform enabling researchers to use AI to scrub through vast troves of images of those dyed cells. Combined, this work makes it easy for a machine to see how cells change when they are impacted by the presence of disease or a treatment. And by looking at every part of the cell holistically – a discipline known as "omics" – there are greater opportunities for making the sort of connections that AI systems excel at.
Using pictures as a way of identifying potential cures seems a little left-field, since how things look don't always represent how things actually are, right? Carpenter said humans have always made subconscious assumptions about medical status from sight alone. She explained most people may conclude someone may have a chromosomal issue just by looking at their face. And professional clinicians can identify a number of disorders by sight alone purely as a consequence of their experience. She added that if you took a picture of everyone's face in a given population, a computer would be able to identify patterns and sort them based on common features.
This logic applies to the pictures of cells, where it's possible for a digital pathologist to compare images from healthy and diseased samples. If a human can do it, then it should be faster and easier to employ a computer to spot these differences in scale so long as it's accurate. "You allow this data to self-assemble into groups and now [you're] starting to see patterns," she explained, "when we treat [cells] with 100,000 different compounds, one by one, we can say 'here's two chemicals that look really similar to each other.'" And this looking really similar to each other isn't just coincidence, but seems to be indicative of how they behave.
In one example, Carpenter cited that two different compounds could produce similar effects in a cell, and by extension could be used to treat the same condition. If so, then it may be that one of the two – which may not have been intended for this purpose – has fewer harmful side effects. Then there's the potential benefit of being able to identify something that we didn't know was affected by disease. "It allows us to say, 'hey, there's this cluster of six genes, five of which are really well known to be part of this pathway, but the sixth one, we didn't know what it did, but now we have a strong clue it's involved in the same biological process." "Maybe those other five genes, for whatever reason, aren't great direct targets themselves, maybe the chemicals don't bind," she said, "but the sixth one [could be] really great for that."
In this context, the startups using AI in their drug discovery processes are hoping that they can find the diamonds hiding in plain sight. Dr. Richmond said that Benevolent's approach is for the team to pick a disease of interest and then formulate a biological question around it. So, at the start of one project, the team might wonder if there are ways to treat ALS by enhancing, or fixing, the way a cell's own housekeeping system works. (To be clear, this is a purely hypothetical example supplied by Dr. Richmond.)
That question is then run through Benevolent's AI models, which pull together data from a wide variety of sources. They then produce a ranked list of misbehaving proteins that answer the question, which can include those that are not linked to the disease." Dr. Richmond added that the model has to provide evidence from existing literature or sources to support its findings even if its picks are out of left-field. And that, at all times, a human has the final say on what of its results should be pursued and how vigorously.
It's a similar situation at Recursion, with Dr. Gibson claiming that its model is now capable of predicting "how any drug will interact with any disease without having to physically test it." The model has now formed around three trillion predictions connecting potential problems to their potential solutions based on the data it has already absorbed and simulated. Gibson said that the process at the company now resembles a web search: Researchers sit down at a terminal, "type in a gene associated with breast cancer and [the system] populates all the other genes and compounds that [it believes are] related."
"What gets exciting," said Dr. Gibson, "is when [we] see a gene nobody has ever heard of in the list, which feels like novel biology because the world has no idea it exists." Once a target has been identified and the findings checked by a human, the data will be passed to Recursion's in-house scientific laboratory. Here, researchers will run initial experiments to see if what was found in the simulation can be replicated in the real world. Dr. Gibson said that Recursion's wet lab, which uses large-scale automation, is capable of running more than two million experiments in a working week.
"About six weeks later, with very little human intervention, we'll get the results," said Dr. Gibson and, if successful, it's then the team will "really start investing." Because, until this point, the short period of validation work has cost the company "very little money and time to get." The promise is that, rather than a three-year preclinical phase, that whole process can be crunched down to a few database searches, some oversight and then a few weeks of ex vivo testing to confirm if the system's hunches are worth making a real effort to interrogate. Dr. Gibson said that it believes it has taken a "year's worth of animal model work and [compressed] it, in many cases, to two months."
Of course, there is not yet a concrete success story, no wonder cure that any company in this space can point to as a validation of the approach. But Recursion can cite one real-world example of how close its platform came to matching the success of a critical study. In April 2020, Recursion ran the COVID-19 sequence through its system to look at potential treatments. It examined both FDA-approved drugs and candidates in late-stage clinical trials. The system produced a list of nine potential candidates which would need further analysis, eight of which it would later be proved to be correct. It also said that Hydroxychloroquine and Ivermectin, both much-ballyhooed in the earliest days of the pandemic, would flop.
And there are AI-informed drugs that are currently undergoing real-world clinical trials right now. Recursion is pointing to five projects currently finishing their stage one (tests in healthy patients), or entering stage two (trials in people with the rare diseases in question) clinical testing right now. Benevolent has started a stage one trial of BEN-8744, a treatment for ulcerative colitis that may help with other inflammatory bowel disorders. And BEN-8744 is targeting an inhibitor that has no prior associations in the existing research which, if successful, will add weight to the idea that AIs can spot the connections humans have missed. Of course, we can't make any conclusions until at least early next year when the results of those initial tests will be released.

There are plenty of unanswered questions, including how much we should rely upon AI as the sole arbiter of the drug discovery pipeline. There are also questions around the quality of the training data and the biases in the wider sources more generally. Dr. Richmond highlighted the issues around biases in genetic data sources both in terms of the homogeneity of cell cultures and how those tests are carried out. Similarly, Dr. Carpenter said the results of her most recent project, the publicly available JUMP-Cell Painting project, were based on cells from a single participant. "We picked it with good reason, but it's still one human and one cell type from that one human." In an ideal world, she'd have a far broader range of participants and cell types, but the issues right now center on funding and time, or more appropriately, their absence.
But, for now, all we can do is await the results of these early trials and hope that they bear fruit. Like every other potential application of AI, its value will rest largely in its ability to improve the quality of the work – or, more likely, improve the bottom line for the business in question. If AI can make the savings attractive enough, however, then maybe those diseases which are not likely to make back the investment demands under the current system may stand a chance. It could all collapse in a puff of hype, or it may offer real hope to families struggling for help while dealing with a rare disorder.