Meta's prototype moderation AI only needs a few examples of bad behavior to take action
The company claims 'Few-Shot Learner' outperforms similar models by an average of 12 percent.

Moderating content on today's internet is akin to a round of Whack-A-Mole with human moderators continually forced to react in realtime to changing trends, such as vaccine mis- and disinformation or intentional bad actors probing for ways around established personal conduct policies. Machine learning systems can help alleviate some of this burden by automating the policy enforcement process, however modern AI systems often require months of lead time to properly train and deploy (time mostly spent collecting and annotating the thousands, if not millions of, necessary examples). To shorten that response time, at least to a matter of weeks rather than months, Meta's AI research group (formerly FAIR) has developed a more generalized technology that requires just a handful of specific examples in order to respond to new and emerging forms of malicious content, called Few-Shot Learner (FSL).
Few-shot learning is a relatively recent development in AI, essentially teaching the system to make accurate predictions based on a limited number of training examples — quite the opposite of conventional supervised learning methods. For example, if you wanted to train a standard SL model to recognize pictures of rabbits, you feed it a couple hundred thousand rabbit pictures and then you can present it with two images and ask if they both show the same animal. Thing is, the model doesn't know if the two pictures are of rabbits because it doesn't actually know what a rabbit is. That's because the model's purpose isn't to spot rabbits, the model's purpose is to look for similarities and differences between the presented images and predict whether or not the things displayed are the same. There is no larger context for the model to work within, which makes it only good for telling "rabbits" apart — it can't tell you if it's looking at an image of a rabbit, or of a lion, or of a John Cougar Mellencamp, just that those three entities are not the same thing.
FSL relies far less on labelled data (i.e. pictures of rabbits) in favor of a generalized system, more akin to how humans learn than conventional AIs. "It's first trained on billions of generic and open-source language examples," per a Wednesday Meta blog post. "Then, the AI system is trained with integrity-specific data we've labeled over the years. Finally, it's trained on condensed text explaining a new policy." And unlike the rabbit-matching model above, FSL "is pretrained on both general language and integrity-specific language so it can learn the policy text implicitly."
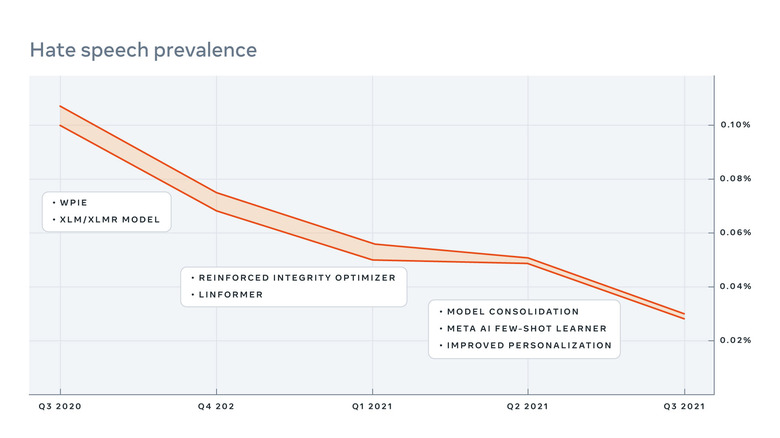
Recent tests of the FSL system have proven encouraging. Meta researchers looked at the change in prevalence of harmful content shown to Facebook and Instagram users before and after FSL's activation on the sites. The system both found harmful content that conventional SL models had missed and reduced the prevalence of that content in general. The FSL system reportedly outperformed other few-shot models by as much as 55 percent (though only 12 percent on average).
FSL's improved performance is thanks in part to entailment, defined as "the act or fact of entailing, or involving by necessity or as a consequence." It's essentially a logical consequence between two sentences — if sentence A is true, then sentence B must also be true. For example, if sentence A is "The President was assassinated," then it entails that sentence B, "the President is dead," is also true, accurate and correct. By leveraging entailment in the FSL system, the team is able to "convert the class label into a natural language sentence which can be used to describe the label, and determine if the example entails the label description," Meta AI researchers explained. So instead of trying to generalize what a conventional SL model knows from its training set (hundreds of thousands of rabbit pics) to the test set ("are these two images of rabbits?"), the FSL model can more broadly recognize harmful content when it sees it, because it understands the policy that the content violates.
The added flexibility of having a "single, shared knowledge base and backbone" could one day enable AI moderation systems to recognize and react to new forms of harmful content far more quickly, catch more content that just barely skirts around current policies and even help Meta develop and better define future policies.