Google's neural network is a multi-tasking pro
It can manage eight tasks simultaneously.
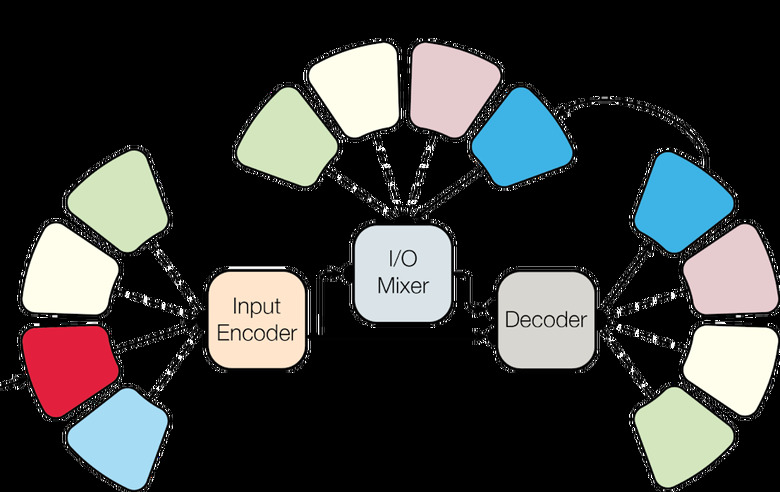
Neural networks have been trained to complete a number of different tasks including generating pickup lines, adding animation to video games, and guiding robots to grab objects. But for the most part, these systems are limited to doing one task really well. Trying to train a neural network to do an additional task usually makes it much worse at its first.
However, Google just created a system that tackled eight tasks at one time and managed to do all of them pretty well. The company's multi-tasking machine learning system called MultiModal was able to learn how to detect objects in images, provide captions, recognize speech, translate between four pairs of languages as well as parse grammar and syntax. And it did all of that simultaneously.
The system was modeled after the human brain. Different components of a situation — like visual and sound input — are processed in different areas of the brain, but all of that information comes together so a person can comprehend it in its entirety and respond in whatever way is necessary. Similarly, MultiModal has small sub-networks for audio, images and text that are connected to a central network.
The network's performance wasn't perfect and isn't yet on par with those of networks that manage just one of these tasks alone. But there were some interesting outcomes. The separate tasks didn't hinder the performance of each other and in some cases they actually improved it. In a blog post the company said, "It is not only possible to achieve good performance while training jointly on multiple tasks, but on tasks with limited quantities of data, the performance actually improves. To our surprise, this happens even if the tasks come from different domains that would appear to have little in common, e.g., an image recognition task can improve performance on a language task."
MultiModal is still being developed and Google has open-sourced it as part of its Tensor2Tensor library.