MIT study finds labelling errors in datasets used to test AI
Over three percent of data in the most-cited datasets was deemed inaccurate or mislabeled.
A team led by computer scientists from MIT examined ten of the most-cited datasets used to test machine learning systems. They found that around 3.4 percent of the data was inaccurate or mislabeled, which could cause problems in AI systems that use these datasets.
The datasets, which have each been cited more than 100,000 times, include text-based ones from newsgroups, Amazon and IMDb. Errors emerged from issues like Amazon product reviews being mislabeled as positive when they were actually negative and vice versa.
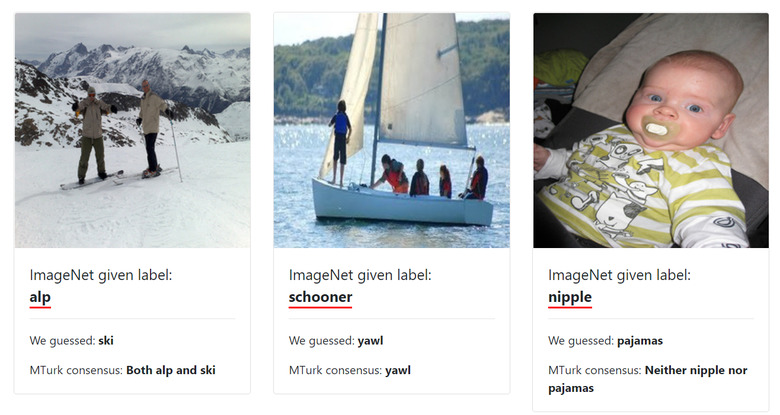
Some of the image-based errors result from mixing up animal species. Others arose from mislabeling photos with less-prominent objects ("water bottle" instead of the mountain bike it's attached to, for instance). One particularly galling example that emerged was a baby being confused for a nipple.
One of the datasets centers around audio from YouTube videos. A clip of a YouTuber talking to the camera for three and a half minutes was labeled as "church bell," even though one could only be heard in the last 30 seconds or so. Another error emerged from a misclassification of a Bruce Springsteen performance as an orchestra.
To find possible errors, the researchers used a framework called confident learning, which examines datasets for label noise (or irrelevant data). They validated the possible mistakes using Mechanical Turk, and found around 54 percent of the data that the algorithm flagged had incorrect labels. The researchers found the QuickDraw test set had the most errors with around 5 million (about 10 percent of the dataset). The team created a website so that anyone can browse the label errors.
Some of the errors are relatively minor and others seem to be a case of splitting hairs (a closeup of a Mac command key labeled as a "computer keyboard" is still correct). Sometimes, the confident learning approach got it wrong too, like confusing a correctly labeled image of tuning forks for a menorah.
If labels are even a little off, that could lead to huge ramifications for machine learning systems. If an AI system can't tell the difference between a grocery and a bunch of crabs, it'd be hard to trust it with pouring you a drink.