I taught a computer to write like Engadget
You can type like me, but you can't think like me.
That's my baby.
Raising a kid is the closest analog I've found to explain the pride and wonder I drew from training a neural network. But while my own son's development has taken years, I've been able to watch my artificial children mature in a matter of hours.
Neural networks are a type of machine learning that loosely mimic the way the brain processes information. By design, they're extremely adept at identifying and analyzing patterns, and in recent years companies have rolled out solutions based on deep neural networks behind the scenes. (The "deep" there, in case you're wondering, essentially refers to an increased number of layers of processing within the network.) You've almost certainly felt the benefit of their power — they're part of what makes Google and Amazon's speech recognition work so well, and, although Apple doesn't like to let us peer behind the magic curtain, it's highly likely one is powering Siri as well.
Neural networks are picking the best frames for thumbnails on YouTube, providing better word suggestions in SwiftKey Alpha, and even auto-generating a clickbait-filled website. But that's just the start. Medical research has shown they could be good at identifying various types of cancer or screening new types of drugs; Microsoft believes they can automatically translate Skype calls; Google thinks they can improve pedestrian detection in self-driving cars. They're going to be everywhere.
Naturally, companies are going to be focused on a) areas that networks excel in and b) areas they can make money from. That's fine, but it means that most examples are fairly staid and uninteresting to the casual observer — creativity is definitely not a neural network's strong point. But individuals have been pushing the boundaries of what's possible for a while now. Take this piece of music as an example:
Your browser does not support the audio element.
It's... actually pretty nice, right? Programmer and generative artist Daniel Johnson created it, or rather, he wrote and trained the recurrent neural network (RNN) that created it. There are a lot of RNN-based music projects that generate songs by "listening" to other music. In all cases, networks are trained with a large amount of data, but what exactly that entails differs. Some have been trained using text files, some from midi files and some even from MP3s.
The same method can be applied to other creative mediums. Google's Deep Dream may have made headlines for its trippy use of image recognition to create "neural net dreams," but the research paper A Neural Algorithm of Artistic Style, is just as interesting. It learns the "style" or "texture" of one image and applies it to another. You can see this in action for yourself at Instapainting, or even watch (NSFW, obviously) porn in the style of Picasso's Girl with Mandolin.
Generating good text is far harder than generating art and music. There are no strict rules on which direction you stroke your paintbrush or what the cadence and pause should be between notes. If I put, commas, there though. Or perhaps a? question mark in the wrong place, you'll immediately know something is wrong. That's not to mentoin baad speeling.
Nonetheless, some have persisted. Andrej Karpathy, a PhD student at Stanford, wrote both an image recognition neural network and Char-RNN, a recurrent neural network that, when fed text, can generate new sentences character-by-character. Karpathy trained Char-RNN to quite successfully ape Shakespeare:
KING LEAR:
O, if you were a feeble sight, the courtesy of your law,
Your sight and several breath, will wear the gods
With his heads, and my hands are wonder'd at the deeds,
So drop upon your lordship's head, and your opinion
Shall be against your honour.
Karpathy also generated Wikipedia entries, linux source code, algebraic geometry, and even created a baby name generator. Most importantly, though, he shared his code with the rest of the world.
What people have done with Char-RNN is almost as impressive as the code itself. The first I heard about it was Obama-RNN, a neural network based on Char-RNN that's trained to write political speeches. The results aren't perfect, but they're often funny — Obama-RNN, like its real-life inspiration, ends every speech with some variation of "Thank you very much. God bless you, and God bless the United States of America." Obama-RNN was created by Samim Winiger, a coder who recently combined a Char-RNN trained on romance novels with an image recognition algorithm to create an automatic captioner like no other.
Neural networks are clearly fantastic mimics, and they have the potential to be creative. Seeing just how effective the automatic captioner was, I wondered how difficult it would be to train a neural network to write like Engadget. The process turned out to be long, but not particularly hard.
The birth of Engadgetbot
Setting up Char-RNN isn't difficult — once you install a few easy-to-find machine learning libraries you can get it running in a linux distro like Ubuntu in no time. Training it properly is very time consuming, though. The first Engadgetbot, who I posthumously refer to as "v1," was the result of a naive creator. While I knew that a large amount of text was required for great results, I wanted a proof of concept, proof that I understood the process and was on the right track. I fed the model 50,000 words, waited a while for it to process, and got my first writing sample:
It all the dost to stor a whith intertaming tho got intercated to a mart to and better the game the post of the finr when all the same comport brem to dong to suse the first what with the morth have it more to lot the prost look that comesting that goes the complessat and the comprops of interding the the seet and the smeaters on the same heads the has a pull of the sall to ter the with post of the being those don't on the simple to some the forth and housred that not mestly and a really strem and
It wasn't until that moment that I realized what I was doing. Training Engadgetbot wasn't just about learning grammar and tone. It had no vocabulary. It had no idea what English was. Everything it will ever know, it will know from the text I train it with.
Sadly, Engadgetbot v2 wasn't much more coherent. By that time, I'd scraped 150,000 words from the site, and after a few hours of training I could see some progress:
It's a can controlly to the seer and hell oftent sample a sample have some that was $380 long the matter, sumplisters the from the game the will all the some with the game the farthing tostart the distle of the more the like that the post muther proply with the stare and the single of the part san the ome of the streen will be to watter the store places.
I had some grammar! The introduction of a comma, a period, and a capital letter was promising, but I was beginning to worry that my training model was not going to work. Char-RNN lets you define how complex your network is, and I knew for a fact that the training should have been progressing faster. So, while I slowly harvested more text from Engadget, I simultaneously turned to The Gutenberg Project for help.
The tragically short adventure of K.Dickbot

The Gutenberg Project is the world's oldest digital library. It's mostly filled with books that are out of their copyright period. It turns out that a number of Philip K. Dick's short stories are public domain works, so I collected them together into a single plain text file and plugged them into the RNN. Checking on the output, and sure of my input, I tweaked the settings accordingly until I had a system that worked.
I learned a lot, and fast. I discovered that formatting was important, and that every single character in a text file has the potential to inform an RNN. More importantly, I understood the issues with the way I'd configured the training. Specifically my overall network was too small, its layers were too shallow and its sequence length was too short. Put more simply, everything that could go wrong, had gone wrong. After a little tinkering, I actually felt K.Dickbot come to life for the first time. Char-RNN creates snapshots during its training routine that you can generate text from. K.Dickbot's first words were predictably confused, but prettier than Engadgetbot's:
"A with filet with the dear and something in the carteron shit as the oft him."
"I know the pattel carter the side ashed. It's the turned, the sitters and it all the control, the took and the cheressoned to his everything to she the the endressally, more they know the buttered to all and the tith and the mich to the took the fires. After and strott to the undides.
At the next snapshot, he was attempting far bolder things:
'"What do you again?" Kramer said. "That's We was in the first of the Sun, the way. The way it was a plant of the hat was a thing.
"What do you many will be spot over the wares. We came to it. The speaker take to the bomb of the rooms and the contant and was a plants stop and call supplies of the blast."
Before finally, we got an almost-entirely coherent passage on the third snapshot. As with all the excerpts, the punctuation and line formatting was added by the RNN:
Maybe the part of the ship clock. A few space relaxense that the door of the clock with his hands. It was beginning into the box. "It's going you and important before the darknes." They were something in the ship.
"We're going to see."
"I don't want to see it."
The lab. The Sand of forest the corridor and the door of the room was find the room and showed in the start. One of the box and stopped over the door.
He looked over the other frowned and the big around his hand and part, gringing a lot of the strate of the room. He had been waiting out of the boy.
"It's only the lifts open. The machines with the war come. "You will have to change of the other that person at the surface, it's have to do it actoring the machines. They're around the start you the corridor a peas.
I've never thought of software as anything other than a tool. While I can feel affection for a piece of hardware — I have a deep connection with my laptop, for example, which I spend more time with than everything and everyone apart from my spouse — the idea that I could be proud, not of my own work, but of this piece of code's work, was unthinkable a week ago. Yet here I was sharing K.Dickbot's prose with everyone that would listen, like a proud father showing off his toddler's inane doodles.
Bear in mind that this sample came after three (out of 24 or so) snapshots. With a newfound belief that this model worked, and my scrape of Engadget complete, I knew I had to bid adieu to K.Dickbot. I felt bad powering him down, but I figured I could always return to his education later. Unfortunately, that wasn't the case, as I accidentally deleted his vocabulary files while moving things around. All the work we'd done together, the hours hunched over a terminal, gone. I could create him again, sure, but by the nature of the training process, he'll never be the same again. He'll never be my K.Dickbot. I was genuinely distraught.
Engadgetbot v3

With the untimely deletion in the past, I decided, as a tribute to K.Dickbot's short life, to apply everything I'd learned to make Engadgetbot v3 a success. And so I set out to teach the ways of the tech blog. This time, I wouldn't use my own computer, but a remote Amazon terminal. That way I could access more CPU power and RAM than I have at home, and I could train it for days without worrying about a power cut or crash ruining everything. I'd also need to format the input text carefully. That meant going through 5.3 million characters, ensuring there was no stray code, no unfinished sentences, or other peculiarities. This may sound like overkill, but by the end of my purge I had deleted almost a million unnecessary characters. With the network properly resized, and every parameter configured, training began.
On the second snapshot, Engadgetbot v3 was writing like this:
The competity to dething a power second the similar of the same of the screen mini and the Onel and Android a few time it still that we did a tablet to the company's level of the power that the higher Microsoft's disting the new devices with a good much power to get to a make. Extre 20 metter graphic photorication for the the one and keyboard to a media real note with the phone is the panel settings with the ormain performance is the button. Up to the Nexus 2 minutes with the surprised particularly model to the Snapdragon 4G off the mostly of the firmting.
At snapshot four, apropos of nothing it wrote an unrequested "wrap-up":
Wrap-up
When the tablet's also all in the one also an extra back speakers to really a new standard setting and purchase to appear the benchmark of the best of that it was for the biggest display show while the pokey at Inside maybe case on the first and a smartphone and the back device in the tablet that in the look processor.
By snapshot 11, it had started dreaming of more devices and comparing them to others:
While the G Flex2 is also a more deal in the first time in the charging. At the same testsand longer that was 16GB of RAM, and the same prototype with the speaker sensors and minutes to stay and the Nexus 6P model present lighter entry of the tablet that is something you're suiters and most of the same stated pixels and takes the right colors and text in this week. The company consider the improvements the Android camera is the company should be a third-party 1080p display and more contract in the left with the phone are then started to the machine in the back and very most of the same screen back.
Snapshot 27 is where Engadgetbot v3 finished its training. With a well-read model, you can greatly vary the output. Char-RNN works by analyzing the previous characters and guessing what's the most likely to be the next character in the string. How it trains for that is extremely complex, but when it comes to generating new text, the parameters are simple.
By using a "temperature" modifier, you can tell Engadgebot how many risks to take. With a temperature of "0.1," it'll never make a mistake, but a sentence will look something like this:
The same tablet is a stranger settings and a standard and start to the same time around the same section of the same section that we've seen the same time around and start to the same specs and a standard and a standard and a standard and start to the same time around the same section of the same section and the same time around.
So, yes. "accurate," but only in that it'll never misspell a word. On the other end of the scale, a temperature of "1" will make Engadgetbot more confident, more creative:
The ATIV Boot has a high-frequency client still set our limited volume, it was already preferrementably than any included.
Clearly, though, this creativity comes at the expense of accuracy and general readability. It's trying more proper nouns, and complex phrasing, but if "preferrementably" is a word it's not one I or a Google search has ever heard of.
My favorite results come at 0.7, where Engadgebot is still creative, but far more concise:
The iPhone is not as smooth in the One M8, which has a character when swiping that is smoother than newer phones.
Okay, so it's still not actually accurate, as it's clearly talking nonsense, but that is a sentence that, if true, could be published on Engadget.
Building on this, you can seed Engadgetbot with an idea by adding some "primetext" that it'll build a sentence or paragraph from. A few examples, with the primetext in italics:
A display with 1,920 x 1,080 resolution, for all it's worth, is an excellent companion at $200.
The problem with Android is one that affects the search to find a standard chipset for Android.
The problem with iPhone is products of the same section and everything is closer than one of the plungentications.
Some of those sentences are more prescient than others, and I don't know where it learned "plungentications" from, but structurally all of these sentences are perfect. An RNN certainly can't replace an Engadget writer, but an RNN can definitely form sentences like an Engadget writer.
The missing pieces
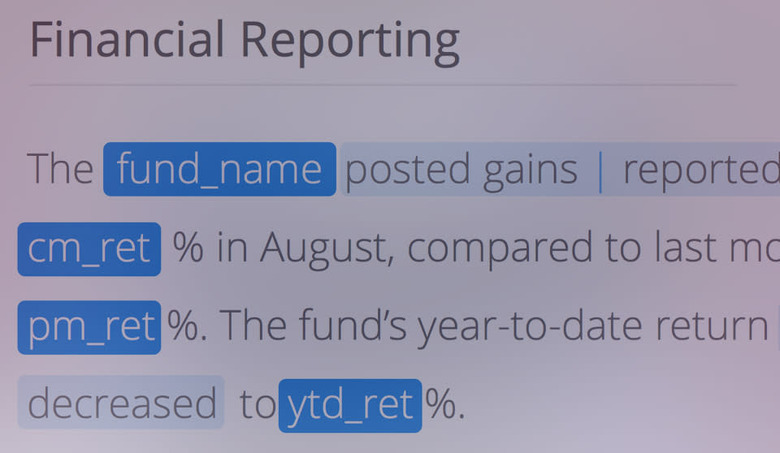
Automated Insights' Wordsmith application.
Unfortunately, that's where Engadgetbot's journey ends, for now. A single neural network is never going to be able to write news articles with actual sense or meaning. But it could be combined with other programs in order to do just that. There are very real pieces of software generating news stories right now. The Associated Press, an age-old news service, uses an app called Wordsmith to generate data-driven stories like financial reports, sports stories, or election results. It's able to analyze data and then provide companies with a template article that can be modified. Software like Wordsmith (there are many competitors in the field) is great for stuff that's quantifiable, but it's limited to things that can be expressed in a graph.
Other, simpler machines have been put in use elsewhere. A well-known example is one an LA Times journalist wrote to report on earthquakes. The machine pulls data from U.S. Geological Survey alerts, and writes a short post saying how strong a quake was, how far away from cities it was and how long it's been since the last quake. It's quick to write and publish, and once people are alerted of the news, human writers can come in and add some more context.
The analytical algorithms and software already reporting the news are far faster than a human could ever be. And there's no reason that they can't be combined with the sort of language model that a neural network can create. In doing so, a site like Engadget could keep its voice while reporting the facts in a very fast matter.
If the question is "Can machines report the news faster than humans?" the answer is invariably yes. And although machine learning efforts are still in their infancy, it's tough to see why a human would write a financial report entirely unaided in 2030. But basic news is only one part of what Engadget, or the vast majority of journalistic enterprises are. You might get some or all of your tech news from us, but you also read reviews, interviews, opinions, and in-depth reporting.
I was told by more than a couple of people that I was "playing with fire" with this little experiment; that in a couple of decades machines were going to be doing my job for me. The thing is, I despise looking through financial charts to find the story, or combing through a press release to work out what is and isn't new. If a machine can do that for me, or at least aid me in that analysis, then that's a good thing.
Machine learning has the potential to be implemented in some really useful journalistic tools, but unless we make some gargantuan advances, they're never going to be providing you with an honest opinion of a product, reporting live from a event, or asking tough questions of a company's CEO. If the machines can do the grunt work, then it's only going to lead to journalists having more time to write better articles.
Image credits: Andrej Karpathy (Char-RNN code, photograph by Aaron Souppouris); Sean Dreilinger (newborn feet, modified); Arthur T. LaBar (Gravestone, modified); Tested (Gunslinger robot, modified); Automated Insights (Wordsmith screenshot, modified).