Competition coaxes computers into seeing our world more clearly
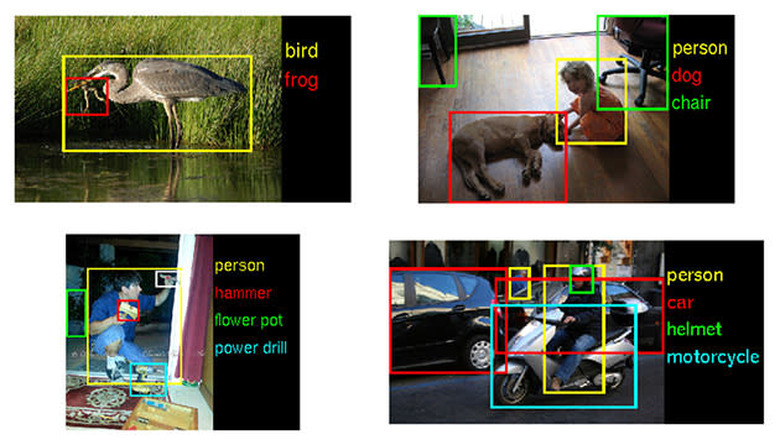
As surely as the seasons turn and the sun races across the sky, the Large Scale Visual Recognition Competition (or ILSVRC2014, for those in the know) came to a close this week. That might not mean much to you, but it does mean some potentially big things for those trying to teach computers to "see". You see, the competition — which has been running annually since 2010 — fields teams from Oxford, the National University of Singapore, the Chinese University of Hong Kong and Google who cook up awfully smart software meant to coax high-end machines into recognizing what's happening in pictures as well as we can.
Surprise, surprise: they haven't bridged that gap just yet, but they're making steady progress. Conference organizers told the New York Times that accuracy nearly doubled this year, while error rates were cut nearly in half. That's a pretty hefty step forward when you consider just what these algorithms were up against — they had to classify discrete objects in scads of images from ImageNet's huge store of human-categorized photos. To hear Stanford AI Lab's Fei-Fei Li put it, though, we're still a ways off from the "holy grail": teaching a machine to grok what's happening in an image in complete sentiments, not just disconnected words.