Google's AI is getting really good at captioning photos
It has open-sourced an algorithm that describes images with 94 percent accuracy.

It's great to be an AI developer right now, but maybe not a good time to have a job that can be done by a machine. Take image captioning — Google has released its "Show and Tell" algorithm to developers, who can train it recognize objects in photos with up to 93.9 percent accuracy. That's a significant improvement from just two years ago, when it could correctly classify 89.6 percent of images. Better photo descriptions can be used in numerous ways to help historians, visually impaired folks, and of course, other AI researchers, to name a few examples.
Google's open-source code release uses its third-gen "Inception" model and a new vision system that's better at picking out individual objects in a shot. The researchers also fine-tuned it for better accuracy. "For example, an image classification model will tell you that a dog, grass and a frisbee are in the image, but a natural description should also tell you the color of the grass and how the dog relates to the frisbee," the team wrote.
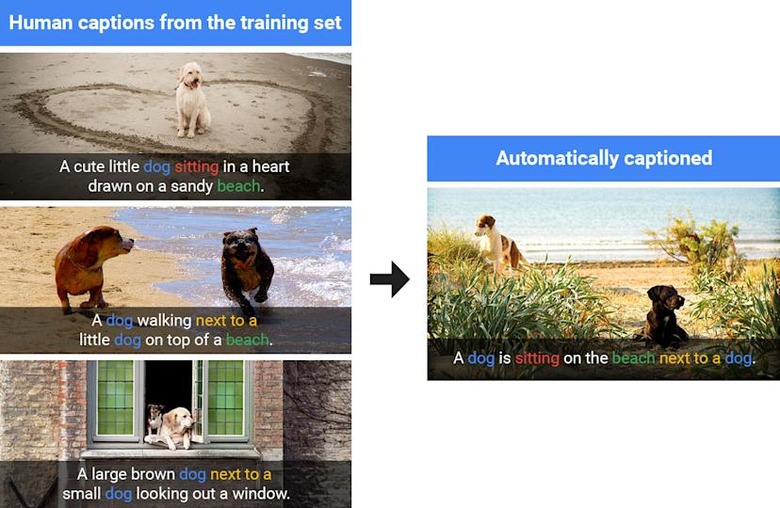
After it was trained using human captions, Google's system was able to describe images it hasn't seen before. "Excitingly, our model does indeed develop the ability to generate accurate new captions when presented with completely new scenes, indicating a deeper understanding of the objects and context in the images," the researchers say. Using several photos of dogs on beach (above), for instance, it was able to generate a caption for a similar, but slightly different scene.
Google has released the source code on its TensorFlow system to any interested parties. To use it, though, you'll have to train it yourself — a process that could take a couple of weeks, assuming you have an NVIDIA Telsa GPU. So, if you were hoping to have it caption your Instagram collection, you'll need to wait for someone to release an already-trained model.