AIs are better gamers than us, but that’s OK
The rise of the machines is all in the name of progress.

We're only just beginning to scratch the surface of what artificial intelligence is capable of, from medical advancements to movie recommendations. Despite AI being a potential goldmine of help to humanity, even the greatest minds are partial to the odd spout of fear-mongering. The robots are coming to take our jobs, overthrow humanity, enslave us and the like. Skynet is but a dystopian dream at this point in time, but in some ways, AI is already winning. It's beating us at some of our favorite games, from Go to StarCraft II. Machine has begun to best man, but that's a good thing.









The most famous historical battle between man and machine took place in May 1997, when IBM's Deep Blue chess computer beat reigning world champion Garry Kasparov under regular tournament rules. An earlier version of Deep Blue had taken a few games from Kasparov the year prior, but winning a full match was something of a watershed moment in computing — a legendary chess player had been outsmarted by lines of code. Alan Turing had suggested that chess ability, given the intricacy and strategy involved, would be a good benchmark of computer intelligence. In fact, 50 years prior to Deep Blue's success, he'd written a primitive chess-playing algorithm himself. And it seemed that at the turn of the century, computers now understood the game better than we did.

The 1997 victory over Kasparov was notable not only for the outcome but for the controversy that followed. Kasparov claimed he saw glimpses of resourcefulness in Deep Blue's moves, leading him to conclude that human players were behind some of its decisions. IBM denied these allegations, declined a rematch and refused to release the log files to Kasparov that would've shown Deep Blue's inner workings — though they were published online years later — before quickly retiring the machine.
Kasparov's defeat to Deep Blue was mainstream news, but it was far from the first time computer programs had faced the best human board-game players. In the summer of 1979, backgammon-playing software BKG 9.8 trounced world champion Luigi Villa in an eight-game match, seven wins to one. Hans Berliner, the writer of the program, believed the luck of the dice had a lot to do with BKG 9.8's success. A year later in 1980, an Othello computer known as Moor took one win in a six-game series versus then world champion Hiroshi Inoue.

Chinook, a program developed to play checkers (aka draughts), was initially conceived at the University of Alberta in 1989. In several matches in the early 1990s, it took on Marion Tinsley, who's regarded as the best to have ever played the game. While Chinook never defeated Tinsley in a match, it won two games — two of the seven games total Tinsley lost throughout his nearly 50-year professional career. Work on Chinook continued until 2007, when the algorithm effectively "solved" checkers. The University of Alberta team was able to prove, using Chinook, that if both sides played a perfect game, the only possible result was a draw.
While these anecdotes represent notable events in computing, where algorithms bested or at least competed with the greatest gaming minds at the time, they are not indicative of intelligence. Instead, they are examples of "brute force" computing: Using raw processing power to calculate every possible exchange of moves, many turns into the future, and selecting the one most likely to lead to victory. The computer players are also incapable of improving without human intervention. In the iconic meeting between Big Blue and Kasparov, for instance, IBM engineers were actually permitted to tweak their algorithm in between games to maximize its performance.
Fast forward nearly two decades since that memorable chess match, and history repeated itself — albeit with an entirely different class of computer playing an immensely more complicated game.
Go was long considered to be out of reach for even the most powerful of machines. The millennia-old game is unlike many others in that, often, there is no single best move. The game evolves as the board becomes more crowded with pieces; strategies must be fluid. In short, Go isn't a mathematical problem you can just throw computing power at. Imagination, in the form of visualizing where the game can go without being able to see every possible future, is key.

Lee Sedol playing AlphaGo in March 2016
It was another defining moment in computing, then, when AlphaGo — a Go-playing AI developed by Google subsidiary DeepMind — beat professional player Fan Hui in late 2015, followed by world champion Lee Sedol the subsequent spring. Not only did AlphaGo win both encounters convincingly but showed creativity in its play that surprised even the most seasoned grandmasters of the game. Some of the move sequences AlphaGo has played have actually influenced how humans approach the game at the highest level.
That's particularly important because it makes the idea of artificial intelligence moving beyond brute-force calculations easier to grasp. While a research paper may be nigh on impossible to understand to anyone outside the field, the use of wholly unconventional moves in match play is a clear indicator AlphaGo has outgrown human tuition. Indeed, the AI was initially trained on a vast dataset of recorded Go matches with which it gained a predictive capacity — a knowledge of likely next moves based on the current makeup of the board.

The rest of its game sense, however, was accumulated more organically, by playing matches against itself. Thousands upon thousands of matches, in fact, and as it improved, so did its opponent. A lifetime of games — more practice than any human could hope to process and convert into applicable experience.
The focus for subsequent iterations of AlphaGo has been on making the system more efficient and minimizing human coaching, whilst preserving the AI's unbeaten record against top professionals. AlphaGo Zero, an AI trained exclusively against itself with the basic rules as its only reference point, surpassed all previous designs after 40 days of training. Building upon this, successor AlphaZero mastered chess, shogi and Go after just hours of training, to the point of being able to beat the best computer competitors in these respective games (including AlphaGo Zero).

Before DeepMind went about creating the best Go player that's ever existed, it worked on an algorithm that learned to play Atari 2600 games on its own. Video games have become a very popular tool in AI research. Understandably so, as they offer not a rigid board game with clear rules but a complex virtual environment and safe space for AIs to develop through reinforcement learning — trial and error (but more nuanced). What's particularly impressive about AIs playing video games is that they are seeing the screen like you or I (as opposed to reading lines of code for information on game state), and trying to make sense of the mess of pixels to figure out mechanics and win conditions.
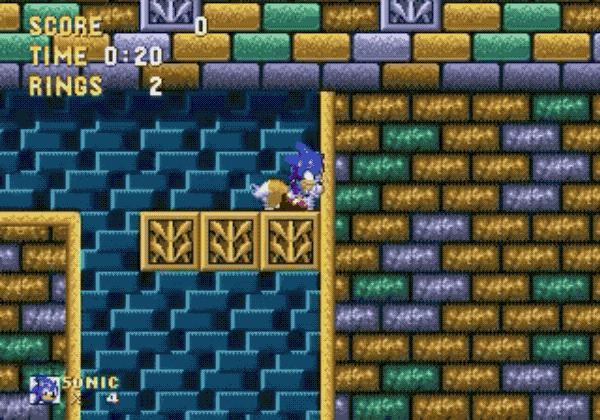
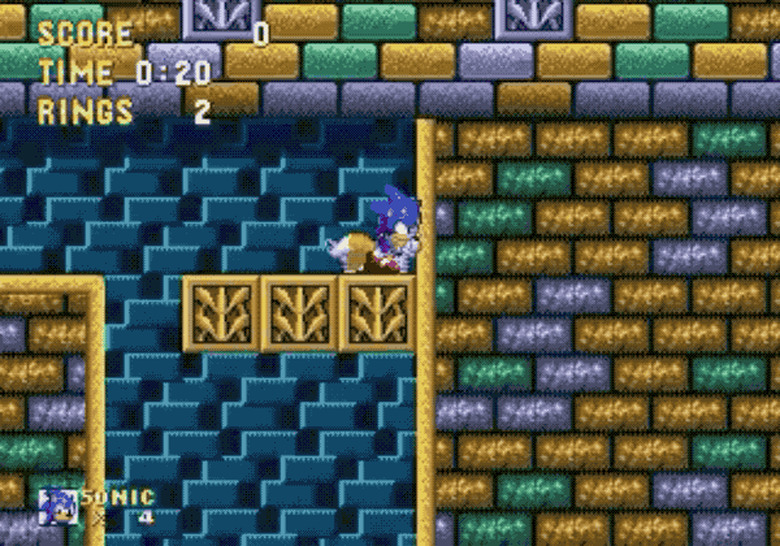
Observing computers playing computer games has resulted in some interesting, unintended behavior. There are many stories of AIs finding previously undiscovered bugs, glitches and skips in games when provoked with a simple reward trigger like a high score or fastest average speed in a racing game. A DeepMind researcher continues to compile a list of these (and other AI phenomena), and just one example is an AI discovering how to clip through walls in a Sonic game in an effort to finish levels as fast as possible to maximize its score. This AI was competing in the OpenAI Retro Contest ran by the research organization co-founded by Elon Musk.
AIs seem to be getting so good at video games that Unity Technologies has developed a title specifically to test the limits of reinforcement learning. Obstacle Tower is a 3D, puzzle-ridden platformer with procedurally generated levels that ensure an AI can't be programmed to carry out a specific set of actions and must, instead, understand the puzzle to complete the level. Currently, participants have access to the first 25 stages, but in mid-April, all 100 floors of the tower will be unlocked for the ultimate challenge. The game is far from easy, too, with each level increasing in difficulty and human players tapping out at around level 15.
In recent years, there have been several notable competitive AI gamers, from MIT's competent Super Smash Bros. Melee fighter to DeepMind's Quake III Arena capture-the-flag specialists, which are better teammates than actual humans. Perhaps the biggest achievement to date, though, was AIs wiping the floor with StarCraft II professionals earlier this year.
StarCraft II is arguably the hardest video game to play at the pro level. It's a fast-paced, real-time strategy in which the player must juggle resource and infrastructure management, controlling multiple units and tactical decision-making, often with incomplete information of what the opponent is up to. The game is as complex as it is unforgiving, with the possibility of one seemingly minor mistake snowballing into a huge, insurmountable disadvantage.

'Starcraft II' main stage at Blizzcon 2017
In the same way AlphaGo was initially trained, AlphaStar was taught the basics of StarCraft II by observing human players. Through this form of supervised learning and by imitating the capabilities of the players it had watched, AlphaStar became a competent competitor. DeepMind then created an internal ladder where many different copies of AlphaStar played against each other. To avoid repetitive matches, each version had slightly tweaked motivations and biases, such as a specific rival on the ladder or a preference to massing a certain unit type, to encourage AlphaStar to explore different strategies.
DeepMind ran this internal ladder for two weeks, which for each individual AI was the equivalent of 200 years of playtime. The five deemed most formidable went on to face two professionals, and all ten games went in favor of AlphaStar. The AI players did have one key advantage: They saw the game map in its entirety, whereas the pros played using the regular StarCraft II interface that only shows a portion of the map at any one time. Furthermore, all games were Protoss mirror matches, meaning the game's other races (which make up for a significant amount of its overall complexity) were off-limits to the human professionals. That said, AlphaStar's reaction times were around 350ms on average, which is sluggish compared to the average meatsack.
To level the playing field somewhat, DeepMind trained another version of AlphaStar to use the standard interface, so it, too, could only process small portions of the map and had to move the camera around. With this added handicap and a shorter training period of one week, one of the originally defeated pros managed to score a victory over AlphaStar in a live-streamed exhibition match.
Dota 2 is another elaborate strategy game in which the best AIs can't quite match the professionals just yet. Last year, at the biggest annual tournament in the Dota 2 calendar, two separate teams of pros took on OpenAI Five — a team of five individual machines — and emerged victorious. In Dota 2, players control just one unit with several active abilities. And it's a team game unlike StarCraft II, which is traditionally a one-on-one affair. Squad coordination, then, is just as important as raw mechanic skill, and it seems us humans are still superior in that regard.
OpenAI Five did have an artificially imposed 200ms response time in its matches with pros. But similar to AlphaStar, which only played with and against one of the three StarCraft races, the Dota 2 players facing the team of five bots had to work within a specific, restrictive ruleset. Dota 2 has over 100 characters to choose from, and a team's playstyle and win condition are dictated heavily by team compositions. Gaining an advantage often begins at the selection screen. In the games with OpenAI Five, other pros picked from a small pool of these characters to promote a balanced match. Beyond that, there are several advanced mechanics the AIs hadn't been introduced to yet that human players were also prohibited from exploiting.

A 'Dota 2' showmatch featuring OpenAI Five
It may be only months or years before AIs master these elaborate strategy games in their entirety and become better players than even the top human professionals. Go was a holy grail of sorts; now, there are new challenges. AIs that can beat us at video games may seem trivial, or mere spectacles designed to make us muse on the line between man and machine. The research underpinning all these endeavors, however, will have far-reaching consequences.
IBM's Watson supercomputer smashing human Jeopardy contestants didn't just make good TV, it was a demonstration of advancements in natural-language processing — the very technology that makes Alexa so amenable to your demands. The same algorithms OpenAI runs its Dota 2 team on are being used to make robot hands move in more agile and human-like ways. Watching an AI learn to drive in GTA 5 might be entertaining, but a distant evolution of that program could be driving your autonomous car one day. AlphaZero might see patterns in Go boards today and diagnose rare conditions in brain scans tomorrow.

Just a few weeks ago, OpenAI announced that it had created a simple MMO specifically for AI to play among themselves. It has procedurally generated terrain, a foraging system that encourages competition for resources and a basic combat system with three classes of characters. The goal of the MMO is to create a sufficiently complex world with short-term and long-term pressures and observe how reinforcement learning works when survival is the only driver.
So far, the research has shown that, quite naturally, players tend to prioritize exploration to avoid conflict in more crowded servers. And that AIs trained in higher-density servers are better survivalists than those born in emptier, less-competitive environments. Right now, it's just thousands of AIs playing their own version of World of Warcraft, but there's no telling what practical applications the research could lead to in time.